Data Warehouse
A data warehouse is a system that collects or stores the data from multiple resources in a single place for reporting and analysis.
Migrating a data warehouse has always been a complex process. You have to think a lot before investing your time and resources. Most of the organizations have relied on traditional data warehouses to collect users data. It is very difficult to maintain and scale the data in those data warehouses to meet today’s business needs. Maintaining and making the data warehouse at regular intervals has been cost effective for the organizations. As an organization you have to plan a strategic approach when turning to cloud data warehousing solutions like Google BigQuery.
Big Query
Google Big Query provides unlimited storage, no-operations, massive scaling and extreme level of performance. Below are the some features of BigQuery which makes it unique:
- Powerful data warehouse engine for Data Science and Analytics.
- Fully managed and serverless.
- Provides real-time analytics on streaming data.
- Automate data delivery and built the foundation for ML.
- Pay only for what you store and queries run.
- Unlimited storage capability
- Exabyte – scale storage
- Petabyte – scale SQL queries
- Encrypted, durable, and highly available.
- Instant and elastic scaling of capacity as per demand.
- Simplify data operations.
- Disaster Recovery built-in.
- Built-in ML and GIS.
- Support of ANSI compliant SQL.
- Query performance across the spectrum of workloads.
- High-speed, in-memory BI engine.
- Easy adoption of new features and tools.
- Elimination of traditional ETL processes and tools.
Process to migrate
You have to move your data from legacy data warehouses to Google Cloud Storage first. Below are multiple Google tools available to move your data:
- Online transfer
- Provides fast and secure data transfers for any dataset or network. Data is encrypted at the time of capture and you decrypt your data once it is transferred into its final storage bucket.
- Gsutil
- gsutil lets you access Cloud Storage from the command line. Can use gsutil to do multiple tasks in Cloud Storage, including: Creating and deleting buckets. Uploading, downloading, and deleting objects.
- Cloud storage transfer service
-
- Allows you to quickly move or backup your online data from other cloud storage providers or from your on-premises storage into Cloud Storage. You can also set up a schedule for transferring the data, as well as transfer data within Cloud Storage, from one bucket to another.
Once you successfully upload to Google Cloud Storage, bq load is the command that takes things from Cloud Storage and drops it into the Big Query. You have to specify the schema and doing this way you got the schema appropriately partitioned and designed inside the Cloud Big Query. You can use the below Google tools to make that happen:
- Dataproc
- Used when you don’t want to change workflows when migrating to cloud. Allow to focus on continuing your Hadoop/Spark workflow/jobs with the power of GCP.
- Dataflow
- Can process batch and streaming data processing in the same pipeline. Can change and transform the data from format into another.
- Dataprep
- Clean and transform the data via web user interface and point interface. Can schedule regular transformation jobs from Cloud Storage/Big Query.
- Federated Query
- Can query directly even when the data is not sorted in Big Query. Instead of loading or streaming the data, you can create a table that references the external data source.
The Migration framework
Recommend following framework to organize and structure the migration work in phases:
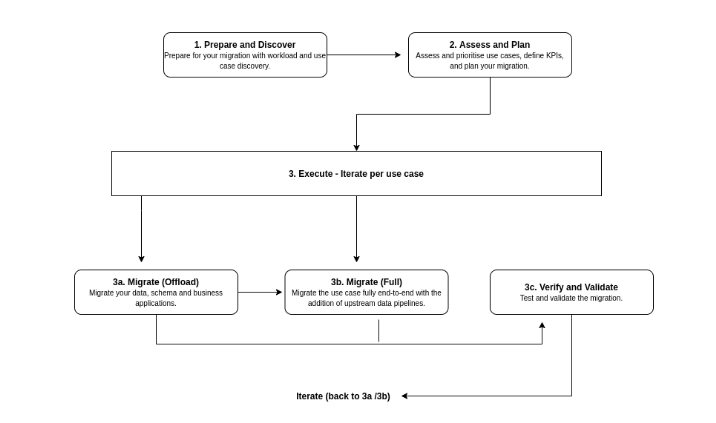
- Prepare and discover
- In the initial phase you have to discover the existing use cases and raise the initial concerns. This process includes defining the value proposition of BQ, performing an earlier TCO (total cost of ownership) analysis, affected use cases by the migration, and modelizing the characteristics of datasets and data pipelines to identify dependencies.
- Assess and plan
- In this phase you take the input from the ‘Prepare and discover’ phase and then use those inputs to plan for eventual migrations. This process includes defining Key Performance Indicators (KPIs), cataloging and prioritizing existing and new cases, checkpoints to make sure that the use case has been integrated, tested and documented, creating time and cost estimations, and Identifying and engaging a migration partner.
- Execute
- Once collecting and prioritizing the information, you can proceed with the migrations in iterations. An iteration can consist of a single or number of use cases related to a single workload. It depends on the interconnectivity, shared dependencies, and the resources of the use cases you have. Each use case is either offloaded or fully migrated and at the end of each iteration every use case should be successfully verified and validated.
Summary
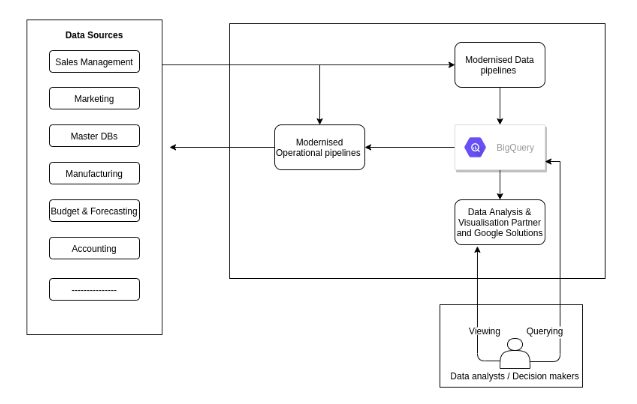
During the migration process you run both existing data warehouse and Big Query and at the end your migration looks like the following: