

Introduction
Kafka was initially evolved at LinkedIn in 2011 and has improved a lot from that point forward. These days it is an entire platform, permitting you to needlessly store absurd measures of information, have a message transport with immense throughput (millions/sec) and utilize real-time stream handling on the information that experiences it at the same time.
This is all well and incredible yet stripped down to its core, Kafka is a distributed, horizontally-scalable, fault-tolerant, commit log.
Distributed:
A distributed framework is one that is split into different running machines, all of which cooperate in a cluster to show up as one single hub to the end-client. Kafka is conveyed as in it stores, gets and sends messages on various nodes (called brokers).
The advantages of this methodology are high scalability and adaptation to internal failure.
Horizontally Scalable:
How about we characterize the term horizontally versatility first. State, for example, you have a customary database server which is beginning to get over-burden. The best approach to get this illuminated is to just expand the assets (CPU, RAM, SSD) on the server. This is called vertical scaling where you add more assets to the machine. There are two major impediments to scaling upwards:
- There are limits characterized by the hardware. You can’t scale upwards inconclusively.
- It as a rule requires downtime, something which huge enterprises can’t bear.
Horizontal scalability is taking care of a similar issue by tossing more machines at it. Including another machine doesn’t require downtime nor are there any breaking points to the quantity of machines you can have in your cluster. The catch is that not all frameworks support horizontal scalability, as they are not intended to work in a group and those that are typically increasingly complex to work with.
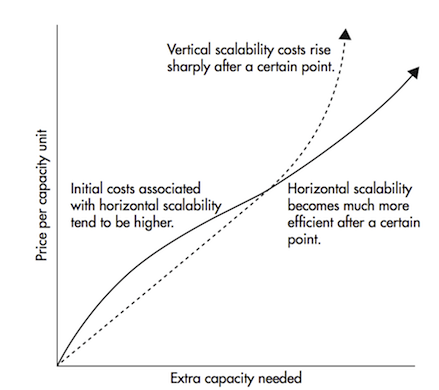
Horizontal scaling turns out to be a lot less expensive after a specific edge
Horizontal scaling ends up being significantly more affordable after a particular edge
Fault-tolerant:
Something that develops in non-distributed frameworks is that they have a solitary purpose of failure (SPoF). On the off chance that your single database server fizzles (as machines accomplish) for reasons unknown, you’re in a bad way.
Disseminated frameworks are structured in such a manner to oblige failures in a configurable manner. In a 5-node Kafka cluster, you can have it keep working regardless of whether 2 of the nodes are down. It is significant that adaptation to internal failure is at an immediate tradeoff with execution, as in the more issue tolerant your framework is, the less performant it is.
Commit Log:
A commit log (additionally alluded to as write ahead log, transaction log) is a tenacious arranged information structure which just backings annexes. You can’t change nor erase records from it. It is perused from left to right and ensures item ordering.
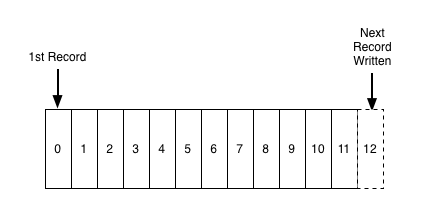
Is Kafka such a simple data structure?
From numerous points of view, yes. This structure is at the core of Kafka and is important, as it gives a request, which thus gives deterministic preparation. The two of which are non-minor issues in dispersed frameworks.
Kafka really stores the entirety of its messages to disk (more on that later) and having them ordered in the structure lets it exploit sequential disk reads.
- Reads and writes are a consistent time O(1) (knowing the record ID), which contrasted with other structure’s O(log N) procedure on disk is a tremendous preferred position, as each disk seek for is costly.
- Reads and writes don’t influence another. Writing would not bolt perusing and the other way around (rather than adjusted trees))
These two things have colossal execution benefits since the information size is totally decoupled from a performance. Kafka has a similar performance whether you have 100KB or 100TB of information on your server.
How does it work?
Applications (producers) send messages (records) to a Kafka node (broker) and send messages are handled by different applications called consumers. Said messages get put away in a topic and customers subscribe to the topic to get new messages.
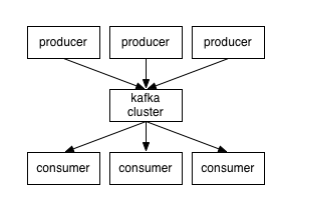
As topics can get very big, they get split into segments of a littler size for better execution and adaptability.
Kafka ensures that all messages inside a segment are requested in the sequence they came in. The way you particular a particular message is through its offset, which you could take as an ordinary array index, a sequence number that is augmented for each new message in a segment.

Kafka follows the standard of a stupid representative and shrewd consumer. This implies Kafka doesn’t monitor what records are read by the consumer and erases them yet rather stores them a set measure of time (e.g one day) or until some size edge is met. Consumers themselves survey Kafka for new messages and state what records they need to read. This permits them to increment/decrement the offset they’re at as they wish, along these lines having the option to replay and reprocess events.
It is significant that customers are really consumer groups that have at least one consumer process inside. So as to stay away from two procedures reading a similar message twice, each partition is attached to just a single consumer process for each group.
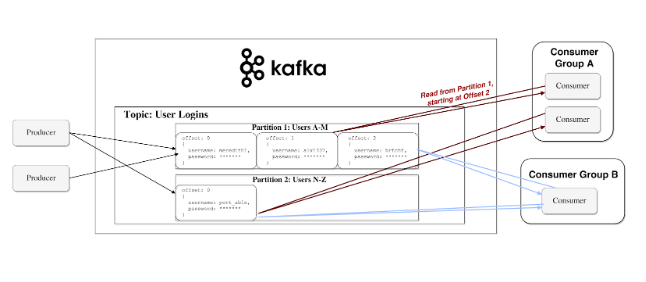
Here is the representation of the data flow
Persistence to Disk
Kafka really stores the entirety of its records to disk and doesn’t keep anything in RAM. You may be thinking about how this is in the scarcest manner a rational decision. There are various optimizations behind this that make it possible:
- Kafka has a convention that groups messages together. This permits network requests to group messages and decreases network overhead, the server, thus, persevere a chunk of messages in one go and consumers get huge direct chunks at once.
- Linear reads/writes on a disk are quick. The idea that cutting edge disks are moderate is a direct result of various disk seeks for, something that isn’t an issue in big linear operations.
- Said linear operations are intensely optimized by the OS, by means of read-ahead and write-behind techniques.
- Modern Operating Systems cache the disk in free RAM called page cache.
- Since Kafka stores messages in an institutionalized binary arrangement unmodified all through the whole stream (producer -> broker-> consumer), it can utilize the zero-duplicate optimization. That is the point at which the OS copies information from the page cache straightforwardly to a socket, adequately bypassing the Kafka agent application totally.
These optimizations permit Kafka to convey messages at close to network speed.
Streaming
In Kafka, a stream processor is whatever takes consistent streams of information from input topics, plays out some processing on this info and produces a stream of information to output topics (or any external services, databases, any place truly)
It is conceivable to do simple processing legitimately with the producer/consumer APIs, anyway for additional complex transformations like combining streams together, Kafka gives an incorporated Streams API library.
Stateless Processing:
Stateless processing of a stream is deterministic processing that doesn’t rely upon anything external. You realize that for some random information you will consistently deliver a similar yield autonomous of whatever else. A model for that would be simple information change for concatenating something to a string.
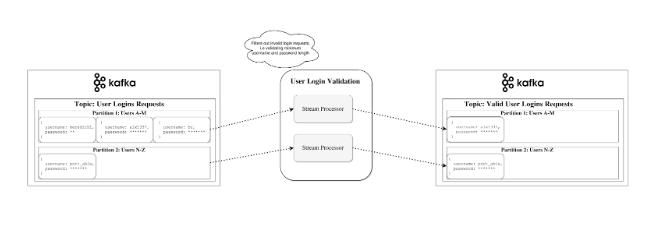 Stream-Table Duality:
Stream-Table Duality:
Recognize that streams and tables are basically the equivalents. A stream can be deciphered as a table and a table can be deciphered as a stream.
Stream as a Table:
A stream can be deciphered as a series of updates for information, in which the total is the conclusive outcome of the table. This system is called Event Sourcing.
On the off chance that you take a gander at how synchronous database replication is accomplished, you’ll see that it is through the alleged streaming replication, where each adjustment in a table is sent to a replica server. Another case of occasion sourcing is Blockchain ledgers — a ledger is a progression of changes also.
A Kafka stream can be interpreted similarly the events which when accumulated structure from the last state. Such stream totals get spared in a nearby RocksDB (by default) and are known as a KTable.
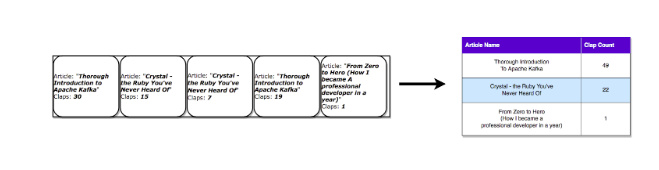
Lets see each record increments the aggregated count
Table as a Stream:
A table can be taken a gander at as a snapshot of the most recent incentive for each key in a stream.
Similarly, stream records can create a table, table updates can deliver a changelog stream.
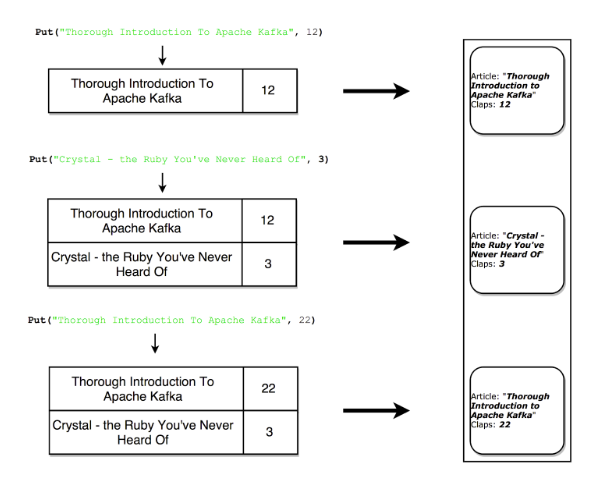
Here, Each update produces a snapshot record in the stream
When would you use Kafka?
As we previously covered, Kafka permits you to have a tremendous amount of messages go through a centralized medium and store them without stressing over things like execution or information misfortune.
This implies it is ideal for use as the core of your framework’s architecture, going about as an incorporated medium that interfaces various applications. Kafka can be the focal point of event driven design and permits you to genuinely decouple applications from each other.
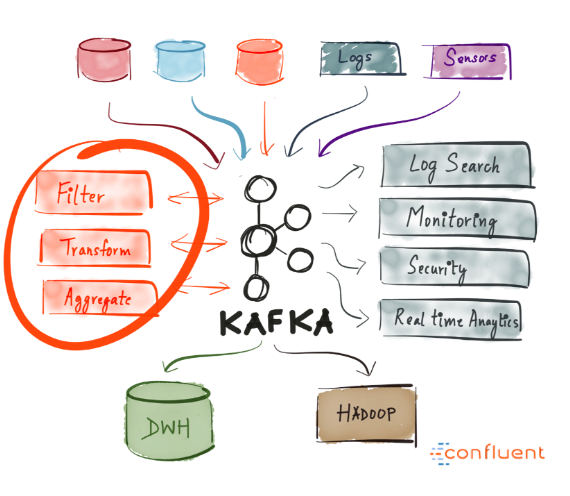
Kafka permits you to handily decouple communication between various (micro) services. With the Streams API, it is presently simpler than at any other time to compose business rationale which enhances Kafka topic data for service utilization. The conceivable outcomes are gigantic and I encourage you to investigate how organizations are utilizing Kafka.
Why has it seen so much use?
High performance, availability and scalability alone are not sufficient explanations behind an organization to receive new innovation. There are different frameworks that gloat comparable properties, however none have gotten so generally utilized. Why would that be?
A real-time event broadcasting platform with durable storage is the cleanest approach to accomplish such engineering. Envision what sort of a wreck it would be if streaming information to/from each assistance utilized an alternate technology explicitly obliged it.
This, paired with the fact that Kafka provides the characteristics (durable storage, event broadcast, table and stream primitives, abstraction via KSQL, open-source, actively developed) make it an obvious choice for companies.
Summary
Apache Kafka is a distributed streaming platform fit for taking care of trillions of events a day. Kafka gives low-idleness, high-throughput, deficiency tolerant publish and subscribe pipelines and can process streams of events.
We went over its fundamental semantics (producer, broker, consumer, topic), found out about a portion of its optimizations (page cache), figured out how it’s deficiency tolerant by reproducing information and were acquainted with its ever-developing amazing streaming capacities.
I trust that this presentation acquainted you with Apache Kafka and its potential.




