
How to use Fibers in Ruby for Concurrency?
How to use Fibers in Ruby for Concurrency?
04 August 2020
Let’s start with definitions
- Concurrency is working on multiple projects. You work on ONE at a time.
- Parallelism is also working on multiple projects. You work on ALL of them at the same time.
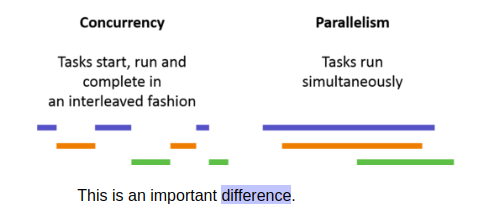
Parallelism requires more CPUs, or CPU cores, but concurrency can make your code faster even with the same amount of CPU cores.
We can implement concurrency in 3 ways
- Processes
- Threads
- Fibers
Threads are the most popular way.
But did you know that they aren’t the most efficient?
Fibers can outperform threads.
What are fibers?
In the Ruby standard library, fibers are lightweight primitives which can be paused, resumed and manually scheduled. In other words, fibers are a concurrency mechanism.
Yes! Similar to threads. With the difference of having more control than threads.
Difference between fibers and threads
- The fibers are lightweight and use much less power than the threads.
- The operating system runs threads and determines when to begin and pause but with fibers, we have to make the decision when to pause, resume manually.
- Threads do their job in the background, but when a fiber runs it becomes the main program before you interrupt it.
How to use fibers?
A fiber is created with Fiber.new(& a block) and it doesn’t run automatically. Rather, it must be explicitly requested to run using the Fiber#resume method.

This will print “foo bar” & gives control back to your main program.
But how to stop a fiber?
By calling the Fiber.yield, we can stop a running fiber. (The yield method used here is different from the yield keyword used to return blocks)
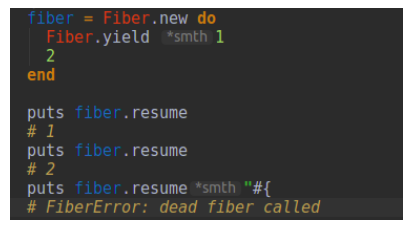
Note: The resumption of this fiber leads to “FiberError: dead fiber called” because there is no code to run anymore.
The Fiber returns the value of the last executed expression upon yield or termination. It’s like pressing a pause button to call Fiber.yield inside a fiber. Allowing you to stop in the middle of loops, or whatever code you write inside a block of fiber. The Fiber#resume method can accept an arbitrary number of parameters if it’s the primary call to resume then they’re going to be passed as block arguments. Otherwise, they’re going to be the return value of the call to Fiber.yield.
Build loops and neverending sequences using fibers
To build an infinite sequence, we can use the Fiber.yield method.
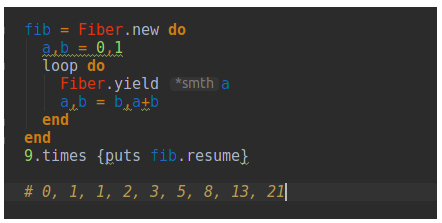
Each fib.resume call flips our execution scope back into the Fiber. When calling Fiber.yield the Fiber returns execution to our main thread. Therefore, we are not stuck in an infinite loop.
Note: Fibers are something you’re obviously never going to use explicitly in application-level code. These are a basic flow-control that you can use to create other abstractions, which you then use in higher-level code.
Using Fibers for Async I/O
Blocking syscalls are the biggest problem to work with, mostly for I/O. A syscall that delays, like a read, will only return until data is available. It ensures that all threads in a process are also disabled in a user space thread model. The answer is to isolate the I/O device from the way it blocks I/O. Another option is to catch an I/O request before it triggers a blocking syscall, issue this non-blocking I/O request and interrupt the Fiber, allowing certain Fiber an opportunity to run. Once the machine receives an answer to the request for I/O, the Fiber could be configured again. Fibers provide a valuable strategic method for applying this principle without forcing users to jump through hoops.