


We all have heard “Use the right tool for the job and not vice versa”, when it comes to app development, choosing the right database is one of the single most important decisions that we’ll ever make. In this blog, we will look at 7 different database paradigms along with some databases you’ve probably heard of and some others that you haven’t. We will look at how they work from a technical perspective, but most importantly we will try to understand what they are best used for.
Our list will start from the most simple type of database and gradually become more complex as we get to #7. This brings us to our first paradigm.
1. Key-Value Database
The database itself is structured almost like a JavaScript object or a Python dictionary, where we have a set of keys and where every key is unique and points to some value.
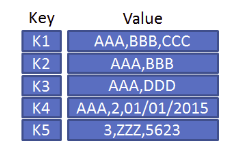
In redis. For example, we can read and write data using commands. We use the set command followed by a Key and Value to write data, and use the get command to retrieve that data in the future. In the case of Redis and MEMcached, all of the data is held in the machine’s memory as opposed to most other databases that keep all their data on the disk, limiting the amount of data you can store. However, it does make the database extremely fast because it doesn’t require a round trip to the disk. In addition, it doesn’t perform queries, joins, or anything like that, so data modeling options are very limited, but again, it’s extremely fast.
Popular databases in this space include Redis, MEMcached.

Uses:
- Most often they’re used as a cache to reduce data latency. Apps like Twitter, GitHub, and Snapchat all use Redis for real-time delivery of their data.
- There are other use cases beyond caching, like Message queues, pub-sub, and gaming leaderboards, but more often than not, key-value databases are used as a cache on top of some other persistent data
2. Wide-Column Database
A wide column database is like, you took a key-value database and added a second dimension to it. At the outer layer, you have a keyspace that holds one or more column families and each column family holds a set of ordered rows, making it possible to group related data together, but unlike a relational database, it doesn’t have a schema, so it can only handle unstructured data. This is nice for developers because you get a query language called CQL that’s very similar to SQL, although much more limited and you can’t do joins but it’s much easier to scale up. Unlike an SQL database, it’s decentralized and can scale horizontally.
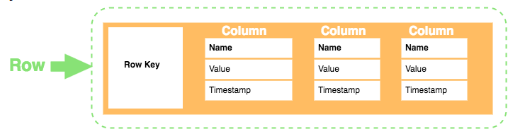
Popular options in this family include Cassandra and HBase.

Uses:
- It can be used for scaling a large amount of time-series data like records from an IOT device, weather sensors, or in the case of Netflix, a history of the different shows you’ve watched.
- It’s often used in situations where you have frequent writes, but infrequent updates and reads.
3. Document Oriented Database
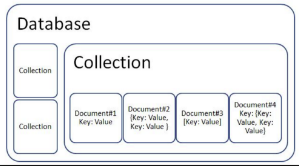
In this paradigm we have documents where each document is a container for key-value pairs. They are unstructured and don’t require a schema. A collection can be indexed and can be organized into a logical hierarchy, allowing us to model and retrieve relational data to a pretty significant degree.
They don’t support joins, so instead of normalizing your data into a bunch of small parts, you’re encouraged to embed the data into a single document. This creates a trade-off where reads from a friend application are much faster and writing or updating data tends to be more complex. These databases are far more general-purpose than the other options we’ve looked at so far. From a developer’s perspective, they’re very easy to use.
Uses:
- They’re often suitable for IoT content management, mobile games, and many other use cases.
- A document database is probably the best place to start if you’re not exactly sure how your data is structured
Popular options in the document family include MongoDB, Firestore, DynamoDB, Couch DB, and a few others.

4. The Relational Database
Document Oriented Databases really fall short when we have a lot of disconnected but related data, which is updated often like a social app that has many users who have many friends who have many comments who have many likes and you want to see all the comments that your friends like. Data like this need to be joined and it’s not easily done in a document database at scale, but we have Relational Databases.
You’re likely to be familiar with this type of database with flavors like MySQL, Postgres, SQL Server, and many others. They continue to be one of the most popular types of databases in today’s world.
But what is a relational database? Well, We can imagine that we have a facility that builds airplanes. The facility is your database, and on that database, you have different warehouses. These warehouses hold different parts like engines, wheels, and so on. Each warehouse is like a database table for holding a certain type of part. Each individual part has a serial number to uniquely identify it, and you can think of an individual part as a row in a table. So now that we have the parts separated into different warehouses.
But how do we build an airplane? That’s where relationships come in. We can build an airplane by referencing the unique ID of the different parts from warehouses. This is known as its primary key. Then it defines its various parts by referencing their IDs. These are known as foreign keys because they reference data in a different table. Now if we want to join all this data together, we can run a query to do that.
A SQL database organizes data in its smallest normal form. However, a potential drawback here is that it requires a schema. If you don’t know the right data shape upfront, they can be a little harder to work with.
Uses:
- SQL databases are also acid compliant, which means whenever there’s a transaction in the database, data validity is guaranteed even if there are network or hardware failures. That’s essential for things like banks and financial institutions.

5. Graph Database
Instead of modeling a relationship in a schema, what if can we just treat the relationship itself as data? Enter the graph database where your data is represented as nodes and the relationships between them as edges.
Let’s imagine we want to set up many to many relationships. In an SQL database, we do that by setting up a join table with the foreign keys that define the relationship. In a graph database, we don’t need this middleman table, we just define an edge and connect it to the other record. We can now query this data using statements that are much more readable. In addition, we can achieve much better performance, especially on larger datasets. It can be a great alternative to SQL, especially if you’re running a lot of joins.
Uses:
- They are often used for fraud detection and finance for building internal knowledge graphs within companies
- They are also used to power recommendation engines like the one used by AirBNB.
Popular options in this space include Neo4J & D graph.

6. A Full Text Search Engine
Now, let’s imagine you want to build something like Google. A user provides a small amount of text. Then your database needs to return the most relevant results from a huge amount of data, that too ranked in the proper order for that, you’re going to want a full-text search engine.
Most of the databases in this space are based on top of the Apache Lucene project, like solar and Elasticsearch. In addition, we have cloud-based options like Algolia and melee search. From a developer perspective, they work very similarly to a document-oriented database. You start with an index, then you add data objects to it.

The difference is that under the hood the database will analyze all the texts in the document and create an index of the searchable terms. So essentially it works just like the index that you would find in the back of a textbook when a user performs a search, it only has to scan the index. As opposed to every document in the database and that makes it very fast even on large datasets, the database can also run a variety of different algorithms to rank those results, filter out irrelevant hits, handle typos, and so on.
And with that, we’ve reached #7.
7. Multi Model Database
There are a few different options out there, but the database we will focus on here is fauna DB which is very different from anything else we’ve looked at so far. With fauna DB you describe how you want to access your data using graph QL.

Consider an example where we have a Todo model. If we upload our graph QL schema into fauna, it automatically creates collections where we can store data in an index to query the data behind the scenes, it’s figuring out how to take advantage of multiple database paradigms like a graph, relational and document, and determining how to best use these paradigms based on the graph QL code you provided.

On top of that, it’s acid compliant, extremely fast, and you never have to worry about provisioning the actual infrastructure. Decide how to consume the data, and let the cloud figure everything else out.




