Google Cloud Dataflow is a fully-managed service to execute pipelines within the Google Cloud Platform ecosystem. It is a service which is fully dedicated towards transforming and enriching data in stream (real time) and batch (historical) modes. It is a serverless approach where users can focus on programming instead of managing server clusters, can be integrated with stackdriver, which lets you monitor and troubleshoot pipelines as they are running. It acts as a convenient integration point where tensorflow machine learning models can be added to process data pipelines.
Google Cloud Dataflow always supports fast simplified pipeline through an expressive SQL, Java, and Python APIs in the Apache Beam SDK. Google Cloud Dataflow allows us to integrate its service with Stackdriver, which lets us monitor and troubleshoot pipelines as they are running. Google Cloud Dataflow provides un-interrupted integration with the GCP services for streaming events ingestion (Cloud Pub/Sub), data warehousing (BigQuery), machine learning (Cloud Machine Learning), and more. Google has already stated that ‘Cloud Dataflow will allow us to gain actionable insights from your data while lowering operational costs without the hassles of deploying, maintaining or scaling infrastructure’.
The Elemental principal of Cloud Dataflow:

Cloud Dataflow: Stream Processing
Google Cloud Dataflow follows stream processing that embosses the computational errors into stages (pipelines) concurrently. Basically, it provides an analytic solution to ingest, process and analyze event streams on a fully-managed infrastructure. By focusing on stream analytics solutions, we can set a faster alternative to batch ETL (Execute-Transform-Load) for getting the maximum value from user-interaction events, application and machine logs. We can ingest millions of streaming events per second from anywhere in the world. Stream analytics in GCP simplifies ETL pipelines without compromising robustness, accuracy, or functionality. Fast pipeline development via expressive Java and Python APIs in the Apache Beam SDK is supported by Cloud Dataflow. This provides a rich set of windowing and session analysis primitives and an ecosystem of the source as well as sink connectors.
Pipelines Contrivances:
Pipelines can run…
- On your development machine
- On the dataflow service on GCP
- On the third party environments like Apache Kafka, Spark or Flink
Running the pipeline encompasses….
- Graph optimization, modular code, and efficient execution
- Smart workers:
- Full lifecycle management
- Auto Scaling can be done (Up and Down)
- Easy monitoring
Some Real-Time frameworks of Google Cloud Dataflow:
-
Facebook Architecture – FLUX
- Flux has a single directional dataflow, meaning additional tasks aren’t triggered until the data layer has completely finished processing. This is the same application architecture that Facebook uses to build client-side web applications. The structural dataflow is in a single direction.

- Flux has a single directional dataflow, meaning additional tasks aren’t triggered until the data layer has completely finished processing. This is the same application architecture that Facebook uses to build client-side web applications. The structural dataflow is in a single direction.
-
Real-time quant trading engine on Google Cloud Dataflow and Apache Beam
- This is the real-time schema of the data pipeline that analyzes real-time stock tick data streamed from gCloud Pub/Sub, runs them through a pair correlation trading algorithm, and outputs trading signals onto Pub/Sub for execution.

- This is the real-time schema of the data pipeline that analyzes real-time stock tick data streamed from gCloud Pub/Sub, runs them through a pair correlation trading algorithm, and outputs trading signals onto Pub/Sub for execution.
-
Fraud detection in financial services
- To improve fraud detection, Google Cloud Dataflow plays a vital role in providing built-in support for fault-tolerant execution that is consistent and correct regardless of data size, cluster size, pipeline complexity.
- To improve fraud detection, Google Cloud Dataflow plays a vital role in providing built-in support for fault-tolerant execution that is consistent and correct regardless of data size, cluster size, pipeline complexity.
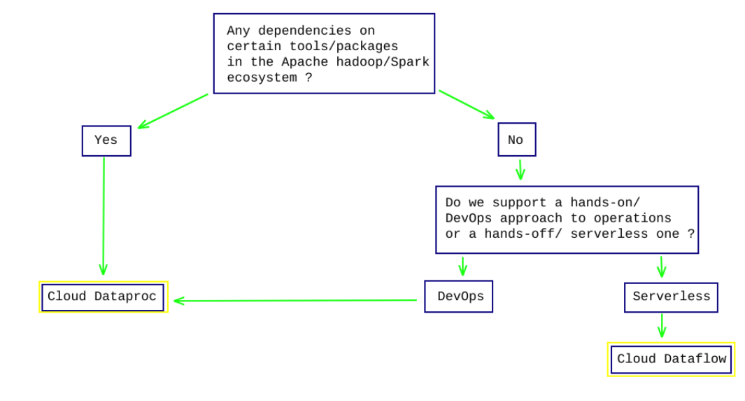
A Big Question: Cloud Dataproc or Cloud Dataflow?
Google Cloud Dataflow and Cloud Dataproc both provide the same usage for data processing and there’s an intersection in their batch and stream processing. Cloud dataflow allows us to build pipelines, monitor execution and transform and analyze data whereas cloud dataproc is a managed service to run Apache Spark and Apache Hadoop clusters in an effortless and more nominal way. As a conjecture, most database technologies have one bent, like batch processing or lightning-fast analytics. Google Cloud Dataflow enumerate ETL, batch processing and streaming real-time analytics amongst its proficiencies.