

Types of Xpath:
Based on the location of node in the HTML document. Xpath is classified into two types:
- ABSOLUTE XPATH If the location of xpath starts with root node or with ‘/'(single slash) then it is an absolute path.
- RELATIVE XPATH If the location of xpath starts with the node that we have selected or with //(double slash) then it is a relative path.
Consider the following example:

Types of nodes in an XPath tree:
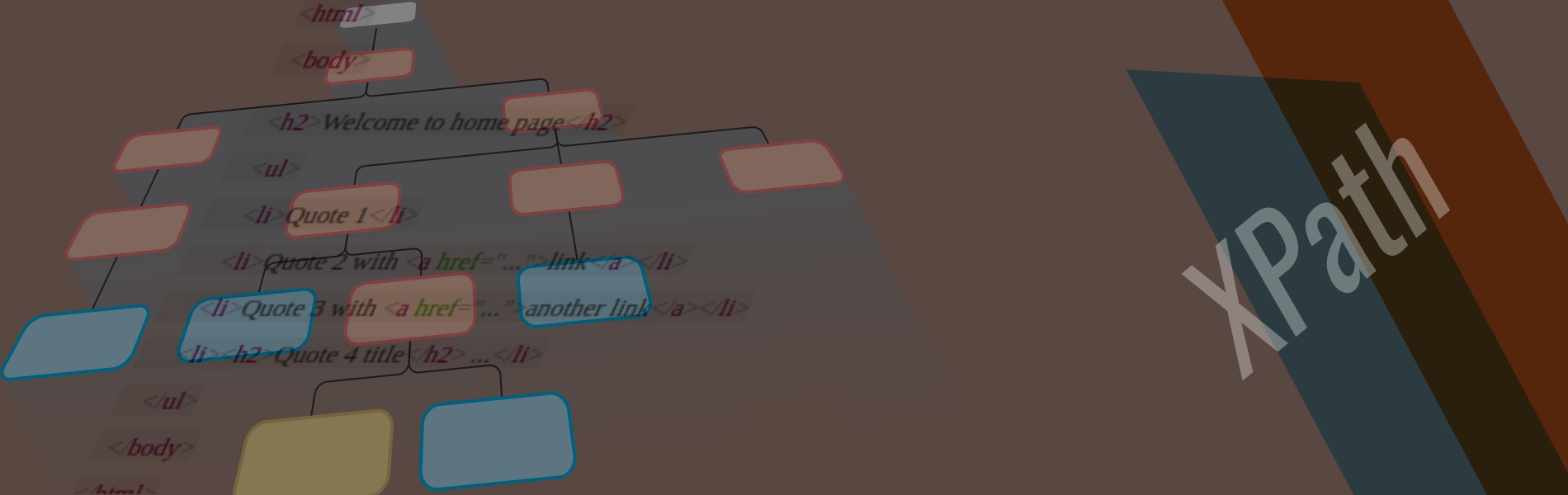
XPath handles the XML or HTML document as a tree. The following figure shows how the Xpath tree for the HTML document looks like: 
Below are the different types of nodes in an XPath tree:
- Element node: represents the HTML element, i.e an HTML tag.
- Attribute node: it represents an attribute in an element node, e.g. “href” attribute in <a href=”http://www.example.com”>example</a>
- Comment node: represents comments in the HTML document which is denoted by (<!– … –>)
- Text node: represents the text enclosed in an element node (example in <p>example</p>)
Now, suppose that if we want the title of the html page by using the xpath expression it should be: /html/head/title Instead of giving the full node path from root of the tree, we can also select them by using: //title, which means it will look into the whole tree, starting from the root of the tree (//) and select only those nodes whose name matches with title.
Some examples of name tests:
| Expression | Meaning |
| /html | Selects node named html, which is under the root of the html document. |
| /html/head | Selects the node named head, which is inside the html node. |
| //title | Selects all the title nodes from the HTML document. |
| //h2/a | Selects all the nodes which are directly under an h2 node. |
Some examples of node type tests:
| Expression | Meaning |
| //comment() | Selects only comment nodes. |
| //node() | Selects any kind of node in the tree. |
| //text() | Selects only the text nodes, for eg. “This is the first paragraph”. |
| //* | Selects all nodes, except comment and text nodes. |
We can also combine name and node tests in a single expression. Let us consider an example: //p/text() This expression selects the text nodes inside of p elements. So from the above example, it will select “This is the first paragraph.” Consider this HTML document:  Suppose we want to select only the first li node from the above example. Then the expression is: //li[position() = 1]. This expression which is enclosed by square brackets is called as predicate and it filters the node set returned by //li. It will checks each node’s position using the position() function, which returns the position of the current node. We can abbreviate the expression above to: //li[1] Both XPath expressions above would select the following element: <li class=”quote”>Quote 1</li>
Suppose we want to select only the first li node from the above example. Then the expression is: //li[position() = 1]. This expression which is enclosed by square brackets is called as predicate and it filters the node set returned by //li. It will checks each node’s position using the position() function, which returns the position of the current node. We can abbreviate the expression above to: //li[1] Both XPath expressions above would select the following element: <li class=”quote”>Quote 1</li>
Some examples of predicate:
| Expression | Meaning |
| //li[position()%2=0] | Selects the li elements at even positions. |
| //li[a] | Selects the li elements which is enclose in an a element. |
| //li[a or h2] | Selects li elements from HTML document which enclose either an a or an h2 element. |
| //li[ a [ text() = “link” ] ] | Selects the li elements which enclose an a element and whose text is “link”. Can also be written as //li[ a/text()=”link” ]. |
| //li[last()] | Selects the last li element in the document. |
We can also combine multiple XPath expressions in a single XPath using the union operator |. It will combine two different xpath into single XPath. For an example, we can select all the a and h2 elements in the document above : //a | //h2 Now, consider this HTML document:  Suppose we want to select only the a elements whose link points to an HTTPS URL. We can do it by checking their href attribute: //a[starts-with(@href, “https”)] This expression will selects all the a elements from HTML document and for each of those elements, it will checks whether their href attribute starts with “https”. We can access any node attribute using the @attributename syntax.
Suppose we want to select only the a elements whose link points to an HTTPS URL. We can do it by checking their href attribute: //a[starts-with(@href, “https”)] This expression will selects all the a elements from HTML document and for each of those elements, it will checks whether their href attribute starts with “https”. We can access any node attribute using the @attributename syntax.
Some examples which uses attribute element:
| Expression | Meaning |
| //a[@href=”https://scrapy.org”] | Selects the a elements pointing to https://scrapy.org. |
| //a/@href | Selects value of the href attribute from all the a elements in the html document. |
| //li[@id] | Selects only li elements from html document which have id attribute. |
If we want to get the element with the help of its text then we can get it by: //*[contains(text(),”This”)] , it will select matches the text “This” in the html document.
It will select 
Suppose if we want to get all the elements between two different specific text in the document. Consider the following example:  Then the xpath of to get the elements is as follows: //*[contains(text(),”Ingredients”)]/../following::div[./following::*[contains(text(),”Directions”)]]
Then the xpath of to get the elements is as follows: //*[contains(text(),”Ingredients”)]/../following::div[./following::*[contains(text(),”Directions”)]]
XPath Axes
An axis represents the relationship between the context node and the nodes relative to the context node in the tree. There are thirteen different types of axes in the XPath axes.
| AxisName | Meaning |
| ancestor | Selects all the ancestors (i.e parent, grandparent, etc.) of the current node |
| ancestor-or-self | Selects all the ancestors (i.e parent, grandparent, etc.) of the current node and the current node itself |
| child | Select all child of the current node. |
| descendent | Selects all the descendents (i.e children, grandchildren,etc.) |
| descendant-or-self | Selects all the descendants (i.e children, grandchildren, etc.) of the current node and the current node itself |
| following | Selects everything in the document after the closing tag of the current node |
| following-sibling | Selects all the siblings after the current node |
| namespace | Selects all the namespace nodes of the current node |
| parent | Selects the parent of the current node |
| preceding | Selects all the nodes that appear before the current node in the document, except ancestors, attribute nodes and namespace nodes |
| preceding-sibling | Selects all the siblings before the current node. |
| self | Selects the current node. It can be abbreviated as a single period (.) |
Wrap up
Xpath is a very powerful and vast topic, this is just an introduction to the basic concepts. If you want to learn more about it, please refer below links:
- http://zvon.org/comp/r/tut-XPath_1.html
- http://fr.slideshare.net/scrapinghub/xpath-for-web-scraping
- https://www.w3schools.com/xml/xpath_intro.asp
One can use online XPath tester (https://extendsclass.com/







